Explosion of content on the Internet
Currently, a lot of information is being published in the Internet as blogs, which are rich in content, frequently published and scattered across numerous sites. MSDN Blogs alone hosts around 2000 blogs. It is very difficult to aggregate this information and get a consolidated view of the same. RSS readers and content aggregators have tried to help us achieve this to some extent, but these tools cannot scale up to handle the voluminous and widespread content in the Internet.
The brain as a better model for describing the Internet
The Internet in its current form represents the collective intelligence of humanity and it has many characteristics that are similar to the human brain. Just like new connections are made between neurons in our brain as we learn new things, as new concepts emerge on the Internet, the links between the documents that describe the concept gets stronger – quite similar to the organic growth that we see in the brain. Also in the brain the connections between the neuron are more important than the individual neuron (though the neuron forms an integral part of the whole, they are far too many to be considered individually). Similarly in the web the concepts that emerge out of connected documents are more interesting than the individual document itself. One might argue that a document(s) authored by a few authoritative person(s) on a subject might be a better representation than the collection of documents made by the whole crowd. Though it might sound counter intuitive, in his work titled 'the wisdom of crowds' James Suriowecki explains that a better representation and a more accurate picture emerges out of the collective decision of the crowd than the work of a selected few. This is also probably one of the factors behind the success of Wikipedia as an accurate encyclopedia.
Currently the most prominent means of getting information from the Internet is through search. This approach is good enough if we already know what we are looking for – or if we know the right question to ask. But if we visit the Internet with the intension of finding something new, a better approach would be to navigate the Internet directory or taxonomy.
Benefit of Folksonomy in favor of Taxonomy
Lets take the previous use-case of browsing through MSDN blogs, looking for something 'new’ and ‘interesting’ – this is a good example of a situation where I wouldn’t know what exactly to search for. Instead of individually going through each blog, I can extract the statistically unique terms to form a taxonomy. My intension in doing this exercise is to distill the contents of more than 2000 blogs into a few words and then pick out (from the resultant set) those terms that I find to be interesting. This can be easily done using TagCloud and the result is as follows.

You can see the original cloud here
Is this auto-generated taxonomy good enough representation of what is published through MSDN blogs? In my opinion-No. This result is purely statistical in nature and I would compare it to the result of Google index with out 'page rank'. It does not take into account the collaborative content selection and filtering that happens usually on the Internet. It is this additional data that makes the data more relevant. A better approximation would be to use the celebrative tagging also referred to as 'Folksonomy'. The term folksonomy is defined in wikipedia as "a neologism for a practice of collaborative categorization using freely chosen keywords. More colloquially, this refers to a group of people cooperating spontaneously to organize information into categories, typically using categories or tags on pages, or semantic links with types that evolve without much central control."
This kind of tagging allows for the kind of multiple, overlapping associations that the brain itself uses, rather than using rigid categories. Such flexibility in using tags is both good and bad. On one hand we have tags like 'blog' and 'blogs' appearing as different tags. On the positive side, a photo of a smiling baby might be tagged 'baby', 'happy' and 'cute'. So in effect folksonomy produces results that more accurately reflect the population's conceptual model of the information.
The need for better tooling
If the brain is a better representative model of how the Internet works then we need different kind of tools to navigate and retrieve information from it. To be able to cope up with the vast amount of information, it should be capable of navigating across concepts instead of across documents. And once we locate our exact match, we should be able to drill down to it. To explain this new UI, lets take the example of Google Earth. To be able to locate a particular spot on earth (which is not previously tagged by Google - hence not available to search), we can take two approaches. The brute force approach would be to hunt through all the locatable points on the surface, until we reach our point. A more efficient strategy would be to zoom out (in other words elevate our self to a higher altitude), where we get an over all picture and then drill down to our point of interest. So to handle more complex problems, we need to create better abstractions. Another benefit of higher abstractions is that, at higher level we can easily spot associations and connections between locations (or concepts) that are hard to find at ground level. In the analogy, just as we are able to navigate across continents, countries and states, we should be able to navigate across concepts that emerge out of the Internet. Another vital feature that is missing in the tools that are currently available is the ability to discover and make connections between concepts. It is this lack of tooling that led me to envision FolkMind.
The vision of FolkMind
To me the new killer app for the Internet should help me in working at any levels of abstraction. The higher the abstraction, the more volume of complexity and data I can handle. Also at any level of abstraction, I should be able to navigate between concepts that are visible at that level and observe new connections that were not apparent to me at a different abstraction. And when I want to dig deeper, it should help me in exploring more on that subject. At the lowest level of abstraction, it would resemble a browser. The mass of the content that is on the Internet will still be on HTML, which is doing a good job of capturing presentation information, and a browser is suitable to view this. In short this application should act as a seamless extension to mind and help me in generating ideas by creating new connection between concepts about which I have little or no previous knowledge by leveraging the collective intelligence of humanity. A 'mind map' would be a good UI (an example of such a UI is shown below) for representing the above-mentioned vision. Wikipedia defines the term 'mind map' as 'a pictorial representation of how a central concept is linked to other concepts and issues'.
As a start we can create a mind map of the existing folksonomy that already exists on the Internet (with data from sites like del.icio.us) and then add new content and nodes to it. In his article entitled "Using Wikipedia and the Yahoo API to give structure to flat lists", Matt Biddulph explains a simple method for automatically converting a set of terms into a connected graph. To me the idea of linking together concepts is quite powerful. Once we reach a critical mass of concepts defined in such a mind map, it can transform itself from a concept management tool to an idea generation tool.
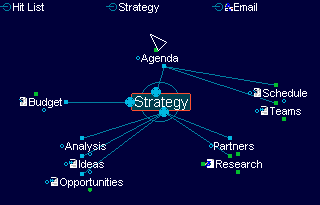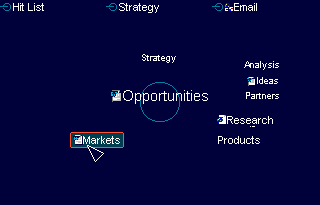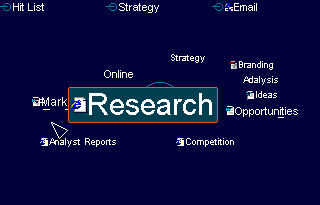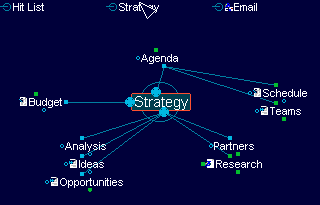
A new person who logs into FolkMind can start with the most popular folksonomy terms and from that point browse related concepts or he can start by searching for a particular concept. Each node in the mind map can be tagged with additional information like a short description, its relevance (based on algorithms similar in principle to the one used by Google page rank), and additional information. This is the highest level of abstraction and at this level the user is more concerned with the connections between concepts than the individual documents that contributed to that concept. With usage the folksonomy gets richer and more concepts and connections between concepts emerge. Once the relevant concepts are identified, the next step is to drill down to the individual documents that pertain to that subject.
If the Internet can be considered as the virtual brain that represents the collective intelligence of humanity, then FolkMind is the pictorial representation on the same expressed as a mind map – hence the name.
How does FolkMind fit in as a Web 2.0 application
Let me explain how FolkMind application demonstrates the traits that are commonly observed in Web 2.0 applications. FolkMind can be a thick client that connects to the FolkMind server to retrieve its content but it uses the client side processing power for rich interactive UI and for local cache. As the user interacts with the UI, any change is reflected back to the server (this is similar to how Google Earth works). Though a user is given the option of marking certain connections as private, all other new connections and nodes that are created by the user will be stored on the server and will be visible to other users. This action is similar to a person creating a bookmark and tagging it using del.icio.us. Thus a user pursuing selfish interests (the motive behind creating a new connection or node is for his own benefit) build collective value for the rest of the users as a side effect. This phenomenon (also referred to, as the network effect) is critical to the success of a Web 2.0 application. As more content gets added to the system and as more users join in, the value of existing users will grow.
Conclusion
As we have seen in this article, the vision behind FolkMind is to be a powerful application with an intuitive, interactive UI that can harness the power of Internet by being capable of handing huge volume of data. Eventually, this will become the virtual brain of humanity!